SciPost's Business Model

Today's Open Access publishing landscape is very polluted and unhealthy:
- APCs (Article Processing Charges) dominate
- predatory profit-making thrives
- in financial dealings, academic institutions are manifestly being outplayed by private corporations.
The consequences include large-scale damage to library budgets, depleted research budgets, and curtailed careers of researchers.
We would like to re-empower the academic side in this battle for Open Access, by offering an alternative designed by and optimized purely for academic interests.
Our business model can be summarized by the following:
We don't charge authors, we don't charge readers, we don't send bills to anybody for our services, and we certainly don't make any profit; we are an academic community service surviving on support from Organizations which benefit from our activities.
Said otherwise, our system is academia's antidote to APCs.
The bullet points here give you the outline; you'll find more detailed explanations below.
- Authors don't pay to publish
- Readers don't pay to read
- Publishing decisions are about science, not money
- We don't make any profit
- We survive only thanks to the charity of those who benefit from our activities
- Publish
We run our publishing activities thinking only about the science. - Report
We interlink each Publication to its associated Organizations; separately, we compile our expenditures for running our services. We make all this information publicly available. - Sustain
We rely on charitable support from Organizations to give us resources to keep doing what we do best, namely point 1.
- Economical
Costs are a fraction of traditional APCs (averaged estimate: €500 per paper). - Transparent
Everybody can see who provides our resources, and who benefits from what we do with resources we are given. - Respectful
Our academic contributors are freed from threatening invoices, bounty hunters, scavenging of research budgets and swiping of credit cards.
How? Bullet points summary
-
Publishing and interlinking
We focus on what we do best: publishing. As part of our production workflow for metadata, Organizations (author affiliations, funding agencies, ...) are interlinked with each Publication to which they are associated. -
Determining PubFracs
Upon publication, we compute our PubFracs (a fraction of a unit representing an Organization's "weight" for a given Publication; see the PubFracs system description below). -
Compiling operational costs
On a yearly basis, we determine and make publicly known:- our total expenditures (with a detailed breakdown, see our yearly reports on the finances page)
- an average expenditure per publication (APEX)
-
Information display
We publicly display relevant information on expenditures and support received:- subsidies we have received
- organizations listing (with one click to organization-level data, where you can find data on each Organization's associated Publications)
- country-level summaries
- an assessment of our current state of viability
-
Sustaining
We liaise with Organizations benefitting from our activities, who can inspect all the data and independently determine to which level they choose to support our activities. Generosity is appreciated, bearing in mind the proportion of non-supporting bystanders. We scale up, maintain or wind down our operations depending on how much support we can gather.
The details
Quick links
Financial pages
First things first: we make all our financial data openly available. This includes all revenues and expenditures for all our activities, aggregated to various levels. The relevant pages are:
- Our Finances page is a good starting point, with many further links and an assessment of our current sustainability status
- Our list of sponsors
- The list of Subsidies we have obtained
- All our annual financial reports
- Our Average Publication Expenditures (APEX) page providing averaged outgoings per Publication per Journal per year
- Our Organizations page, where all instances which have benefitted from our activities are listed; clicking on one will lead you to that instance's detail page.
To start: 3 key concepts
Number of Associated Publications
An Organization's Associated Publications is the set of papers in which the Organization (or any of its children) is mentioned in author affiliations, or in the acknowledgements as grant-giver or funder.
The Number of Associated Publications is always given for a particular context (for example for a given year and/or Journal, or for all years and Journals combined).
A fraction of a unit representing an Organization's "weight" for a given Publication.
The weight is given by the following simple algorithm:
- First, the unit is split equally among each of the authors.
- Then, for each author, their part is split equally among their affiliations.
- The author parts are then binned per Organization.
By construction, any individual paper's PubFracs sum up to 1.
For a given Journal for a given year, the average expenditures (namely: all our outgoings, in salary and others, faced by our initiative) per Publication which our initiative has published.
All our APEX are listed on our APEX page.
Lost in terminology? All important concepts and their definition (click to toggle)
| Concept | Acronym | Definition |
|---|---|---|
| Associated Publications | An Organization's Associated Publications is the set of papers in which the Organization (or any of its children) is mentioned in author affiliations, or in the acknowledgements as grant-giver or funder. | |
| Number of Associated Publications | NAP | Number of Associated Publications, compiled (depending on context) for a given year or over many years, for a specific Journal or for many, etc. |
| Publication Fraction | PubFrac | A fraction of a unit representing an Organization's "weight" for a given Publication. The weight is given by the following simple algorithm:
|
| Expenditures | We use the term Expenditures to represent the sum of all outflows of money required by our initiative to achieve a certain output (depending on context). | |
| Average Publication Expenditures | APEX | For a given Journal for a given year, the average expenditures per Publication which our initiative has faced. All our APEX are listed on our APEX page. |
| Total Associated Expenditures | Total expenditures ascribed to an Organization's Associated Publications (given for one or many years, Journals etc depending on context). | |
| PubFrac share | The fraction of expenditures which can be associated to an Organization, based on PubFracs. This is defined as APEX times PubFrac, summed over the set of Publications defined by the context (e.g. all Associated Publications of a given Organization for a given Journal in a given year). | |
| Subsidy support | Sum of the values of all Subsidies relevant to a given context (for example: from a given Organization in a given year). | |
| Impact on reserves | Difference between incoming and outgoing financial resources for the activities under consideration (again defined depending on context).
|
The PubFracs system a perfect antidote to APCs
One of the many failures of APCs (Article Processing Charges) is to not offer a sufficiently fine-grained resolution of each paper's relations to particular Organizations. A paper is usually associated to many Organizations (multiple authors with their individual affiliations; multiple granting agencies etc). APCs are great if you are the business sending the invoice. APCs are a nightmare for academic Organizations caring about equitable cost distribution.
In order to resolve things more finely, and in the belief that equitable is computable, we built our systems based on the idea of PubFracs, in which each paper has one unit to be distributed among the Organizations associated to that paper.
The PubFrac weight is given by the following simple algorithm: first, the unit is split equally among each of the authors. Then, for each author, their share is split equally among their affiliations. The results are then binned per Organization. By construction, any given paper's PubFracs sum up to $1$.
At the moment of publication, PubFracs are automatically compiled and linked to the relevant Organizations. This data is displayed on our Organization detail pages, where further relevant information can also be found (e.g. associated publications, authors, support history).
Reporting to all stakeholders: how and where we display information
The APEX page
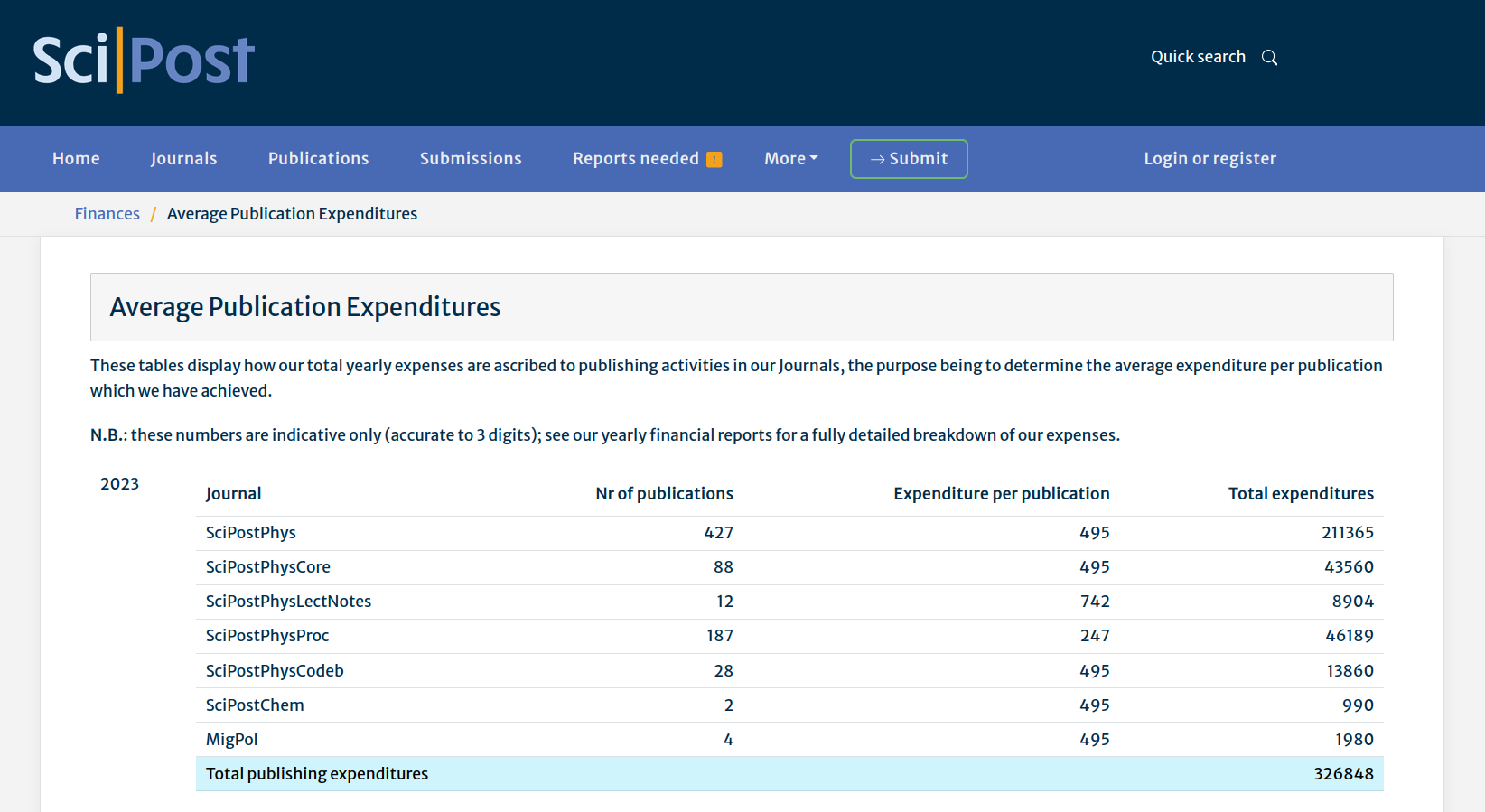
You will find a detailed listing of our Average Publication Expenditures at our APEX page.
This displays a year-by-year, Journal-by-Journal overview of the expenditures we have ascribed to our publishing activities.
These numbers are computed according to the following algorithm:
- Each Journal is given a relative weight, to represent the typical amount of resources it takes on our side in order to guide it through refereeing, decision, proofing and publication. Our flaship Journals are given weight 1. Heavier units like Lecture Notes are given 1.5, whereas simpler units like Proceedings are given 0.5.
- Our financial statements are compiled, giving the total outgoings in a given year.
- The total outgoings are divided by the sum of (weight for Journal) times (number of papers in that Journal in a given year), giving the APEX for weight-1 Journals. The APEX for other Journals are then obtained by scaling this according to the Journal's weight.
The APEX of our Journals fluctuates from year to year, since it depends on our levels of activity (variations in submission and acceptance rates) and our operations (team size, etc.). As a rule of thumb, our APEX is about a factor of 5-7 lower than typical APCs from corporate publishers.
Country-level data
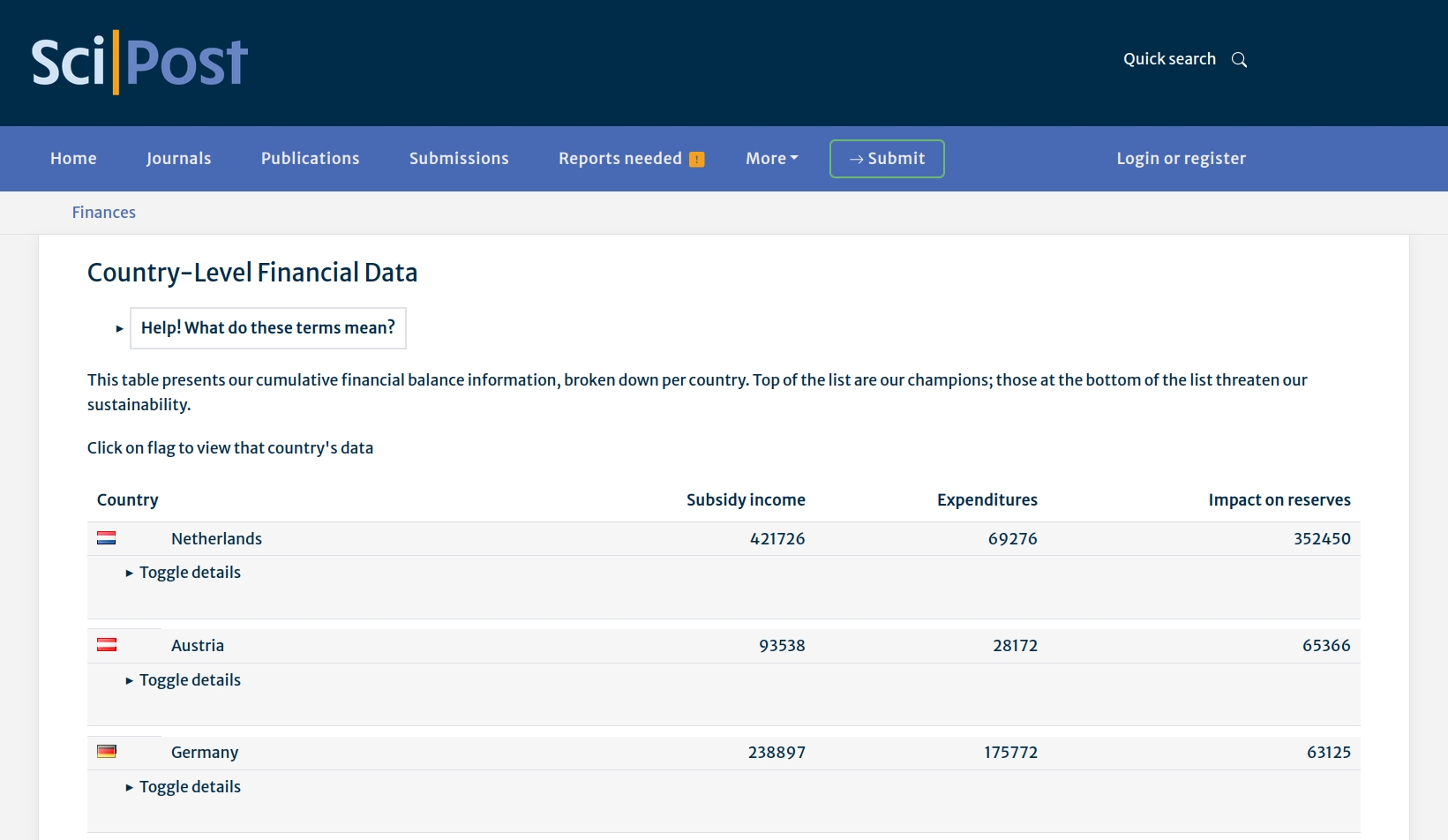
At the country-level financial data page, you will find a list of countries with associated expenditures, subsidies and how this impacts our financial reserves.
In an ideal world where each Organization equilibrated their support to what we deliver for them, all these impact numbers would tend to zero. In the meantime, we survive with the generosity of some to help compensate for bystanders.
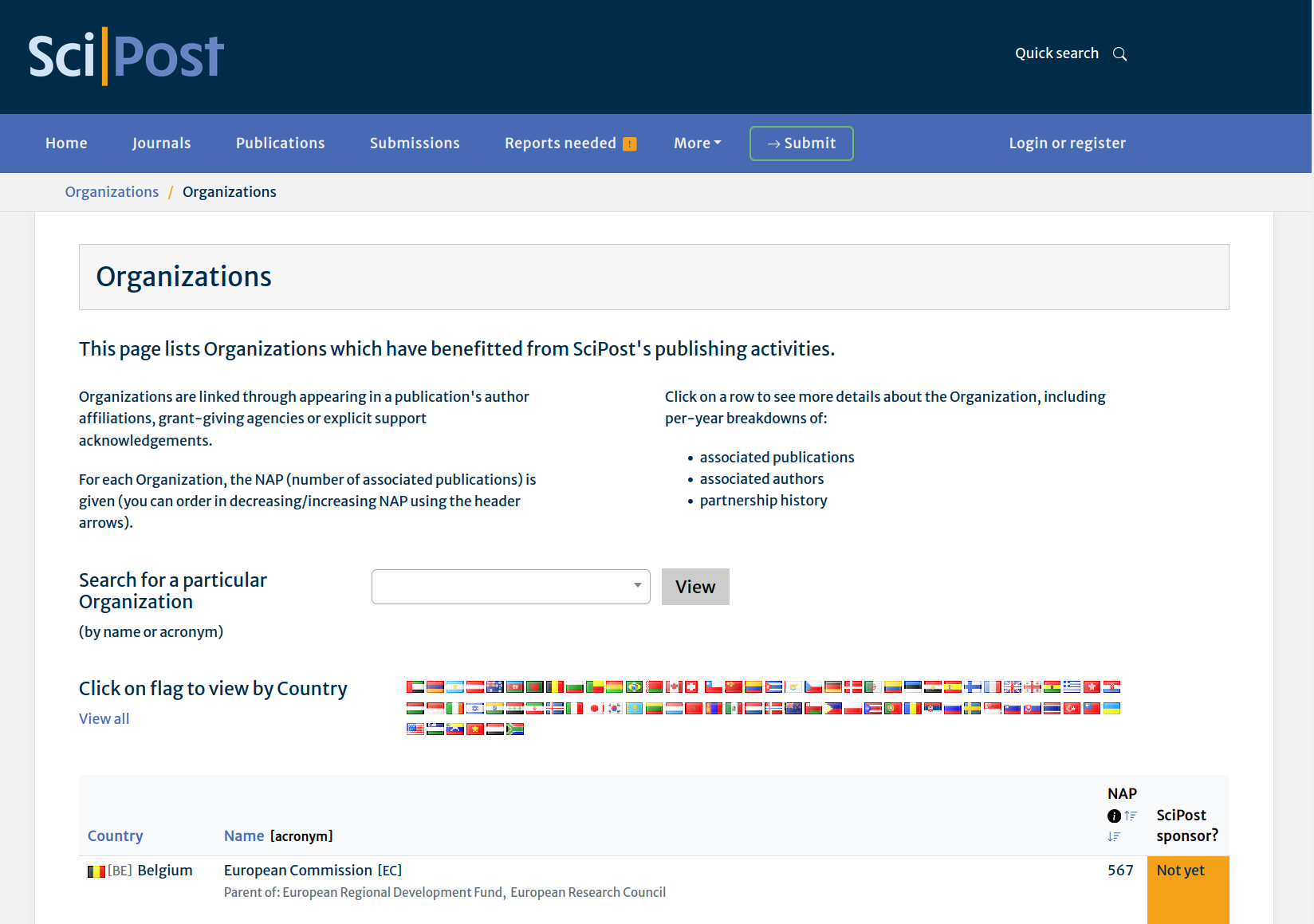
The Organization list page
At the Organization list page, you will find a list of institutions related to our publishing activities.
The list can be filtered by country, or by searching for a particular Organization through its name or acronym.
Each Organization's NAP (summed over all our activities) is displayed, together with an indication of whether they have supported our activities or not (yet).
Clicking on a particular instance leads to that instance's detail page.
An example Organization detail page
(Support history tab)
In an Organization detail page, under the Support history tab, you will find:
- a list of Subsidies we have received from this Organization
- a table containing a compilation, per year, of PubFracs-related information, including how these activities impacted our financial reserves
- as a collapsible for each year, a table giving PubFrac information down to the per-Journal-per-year level
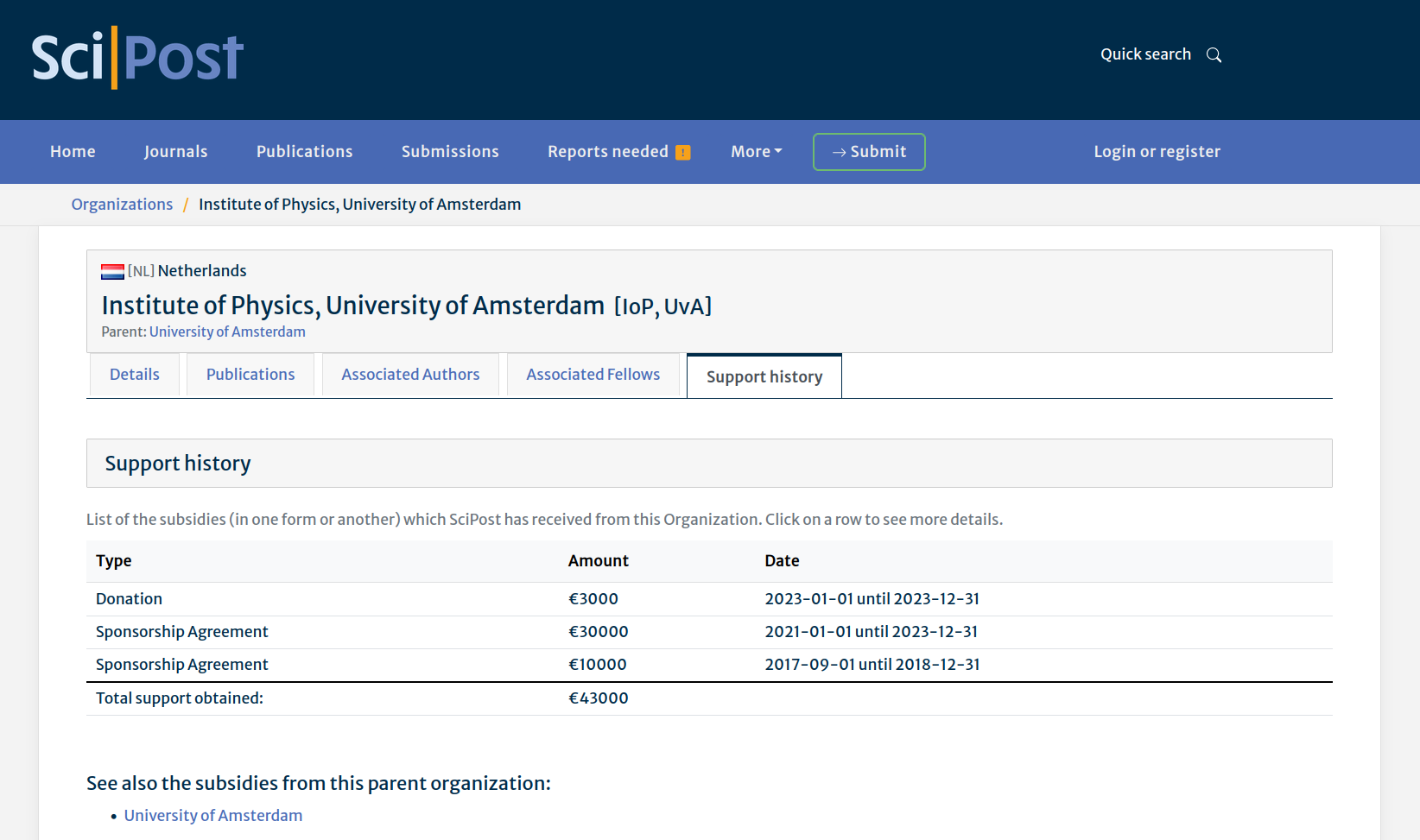
Below the Subsidies list, you will find the per-year data on how these activities impact our financial reserves.
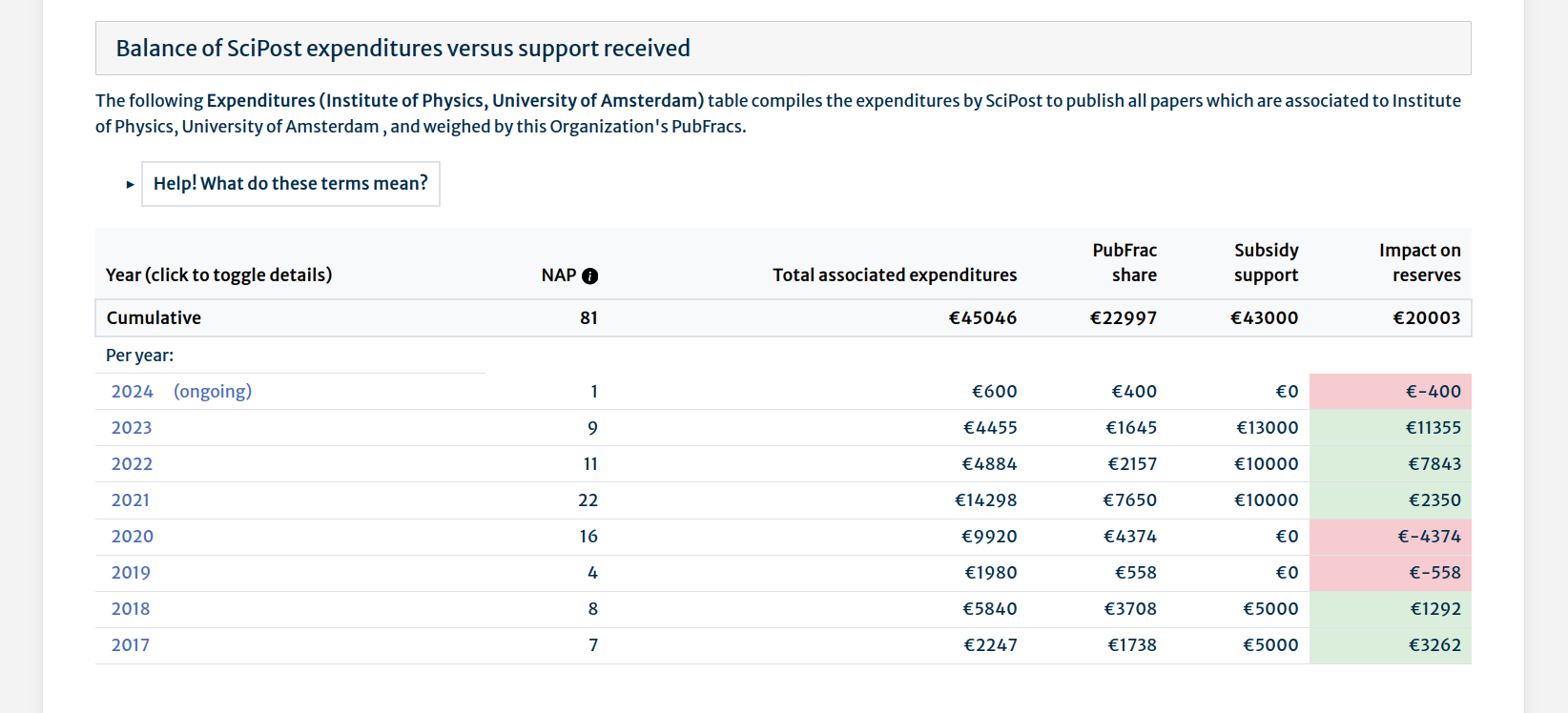
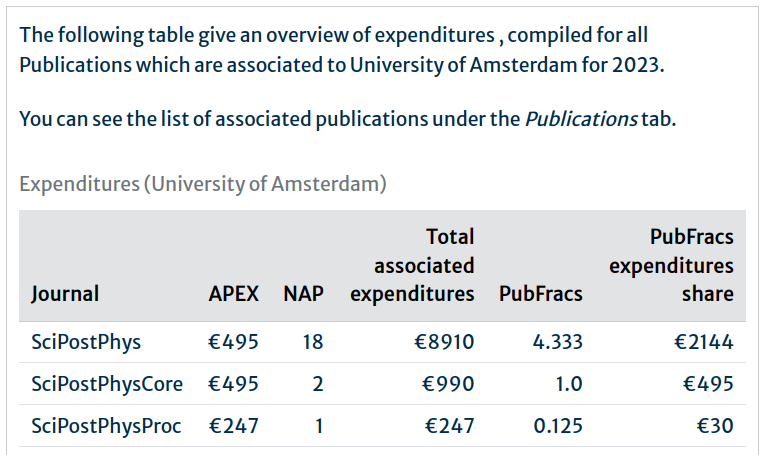
Expanding one of the per-year collapsibles reveals a table with a breakdown of PubFracs at the individual Journal level for that year.
Sponsorship
Why?
It is very important to understand that although we compile data on which Organizations benefit from our activities, we do not bill these Organizations for the services we provide. We are a charity whose mission is to serve the global academic community, and our editorial services are neither for sale nor delivered against payment.
This opens up some frequently-asked questions:
- why would any Organization donate anything?
- isn't this simply letting "free-riding" Organizations get substantial value on the back of those that -do- contribute?
Our operations would be immediately sustainable if Organizations benefitting from our activities generally supported us at a level commensurate with their PubFrac share.
The inevitable reality is that some Organizations will remain bystanders, while others do support us more than others. In practice, sustainability thus means equilibrium between
- the positive impact of the generosity of Organizations supporting us above their PubFrac share
- the negative impact on our reserves from Organizations which act as mere bystanders
Levels of support
Organizations fall somewhere in the spectrum between those that generously support our activities and fuel our growth, all the way to those that remain bystanders. In fact, we like to categorize them as follows:
| Category | Support (vs PubFrac share) |
Impact on our reserves |
|---|---|---|
| Champion | 4x or more | strongly positive |
| Promoter | Twice or more | positive |
| Supporter | On par | neutral |
| Sympathizer | Below | negative |
| Bystander | None | strongly negative |
If we could have all Organizations which benefit from our activities land in the Supporter category, we'd be robustly sustainable. Any Promoters or Champions would then propel our growth. In the meantime, they allow us to survive.
In-kind support
Sponsorships allow us to cover our central personnel and operational costs, and are absolutely crucial to our sustainability. They are however not the only way Organizations can concretely help us in our mission.
We also welcome in-kind support from Organizations, in any useful form including (but in no way limited to):
- sponsorship coordination
Is someone (perhaps a library employee or Open Access officer?) willing to help us run our sponsorship scheme, by for example acting as national/regional contact person or coordinator? - development assistance
Does your Organization have an ICT service with professional-level web programmers? Is any one of them open to the idea of contributing to our project, even on an occasional basis? We can then give them access to our repository at git.scipost.org where we keep all codebases for our online facilities. - editorial coordination
Does your Organization already have editorial-level staff with broad knowledge of best practices regarding plagiarism, reviewing, archiving, metadata maintenance etc? Within our infrastructure, it is easy for such qualified personnel to contribute to the running of our workflows.
In-kind support is particularly interesting for us for the following reasons:
- it helps Organizations which benefit from our activities to maintain a close relationship with us, to be well aware of our current activities and development plans, and to help us set priorities for the future
- it provides a channel for significantly useful but non-financial support; this can be particularly interesting for institutions which are facing financial pressures but nonetheless have qualified personnel willing to help
- it helps making clear that our initiative belongs to the academic community
- in view of the fact that our initiative is resolutely international, it helps us to remain aware of and cater for national/regional/local preferences and ways of working.
Is your Organization interesting in helping us with such in-kind support? Please contact our administration to discuss concrete possibilities.
Why do we push for this business model?
We view our model as the cheapest, fairest, simplest model which an academic publishing infrastructure can adopt.
A subscriptions-based model is out of the question because it is incompatible with our core guiding principles.
We are also against the author pays model, often implemented through Article Processing Charges (APCs). Why? Besides being arguably quite insulting to scientists,
- APCs entangle editorial and financial issues in publishers' operations
- researchers worldwide cannot uniformly afford publication charges
- for a multi-author paper, who should pay? Most publishers make it administratively difficult to share costs among researchers
- the handling of APCs for each individual publication is a substantial time- and resources-wasting accounting exercise.
Our consortial funding model with PubFracs-based recognition solves all these problems in one go. Our pooling of resources and maximally simple accounting drastically simplifies administration for everybody involved. Our transparency means that recognition is given where it is due.
Closing words
As far as our operations are concerned, we run them in the most efficient way possible, with complete transparency, for the benefit not only of scientists worldwide, but also of their supporting Organizations (and anybody else interested in science).
On the question of free-riding, there will of course always be Organizations which are better than others at taking responsibility for themselves, and for the broader community. Though we do not ban free-riding, it does make our model more challenging to sustain. However, since our integrated costs are dramatically lower than those of other publishers, our infrastructure remains cheaper for our sponsors to fund even if some level of free-riding is present. And besides, since we make all data public, who deserves credit for supporting us will be clear and transparent for everybody to see.
As far as our sustainability is concerned, we put our trust in the hands of the Organizations which benefit from our activities.